


Happy New Year!💫
On this post, I’m writing a deep analysis!
On my wish list, the most anticipated AI breakthrough in 2026 is Grok 5 competing against human professional players in League of Legends (LoL), a Multiplayer Online Battle Arena (MOBA), which is a subgenre that evolved from real-time strategy games.
Why is it the most anticipated in 2026 on my list?
Let’s check the two key implications first:
👉(1) Real-time intelligence under extreme latency constraints:
Grok 5 would need to react extremely quickly to make real-time decisions in-game while still remaining generally intelligent in other domains, such as language understanding and chain-of-thought reasoning.
Does OpenAI Five make a Grok 5 League-of-Legends win less impressive? 😆
By comparison, OpenAI Five (2018) proved an important point: with enough self-play and compute, a machine can reach pro-level performance in Dota 2, a complex 5v5 Esports game.
However, OpenAI Five was a narrow intelligence, not a general one. It could not read or understand English, French, or any other human language. It had no chain-of-thought and no System 2–style reasoning. It could not write a poem, solve a math problem, or tackle anything like Humanity’s Last Exam. So, it can not read UI elements from pixels (icons, small text, minimap signals).
Moreover, OpenAI Five as well as AlphaStar (2018) from Deepmind has a privileged state access, which allows it to read internal game state through a specially designed interface rather than reconstructing everything from pixels.
The proposed Grok 5 LoL is stricter, it is only allowed to parse the monitor feed like a human through camera-only input. And its click rate is no faster than humans.
How to build a LLM with chain-of-thought to make super fast decisions? 🤯
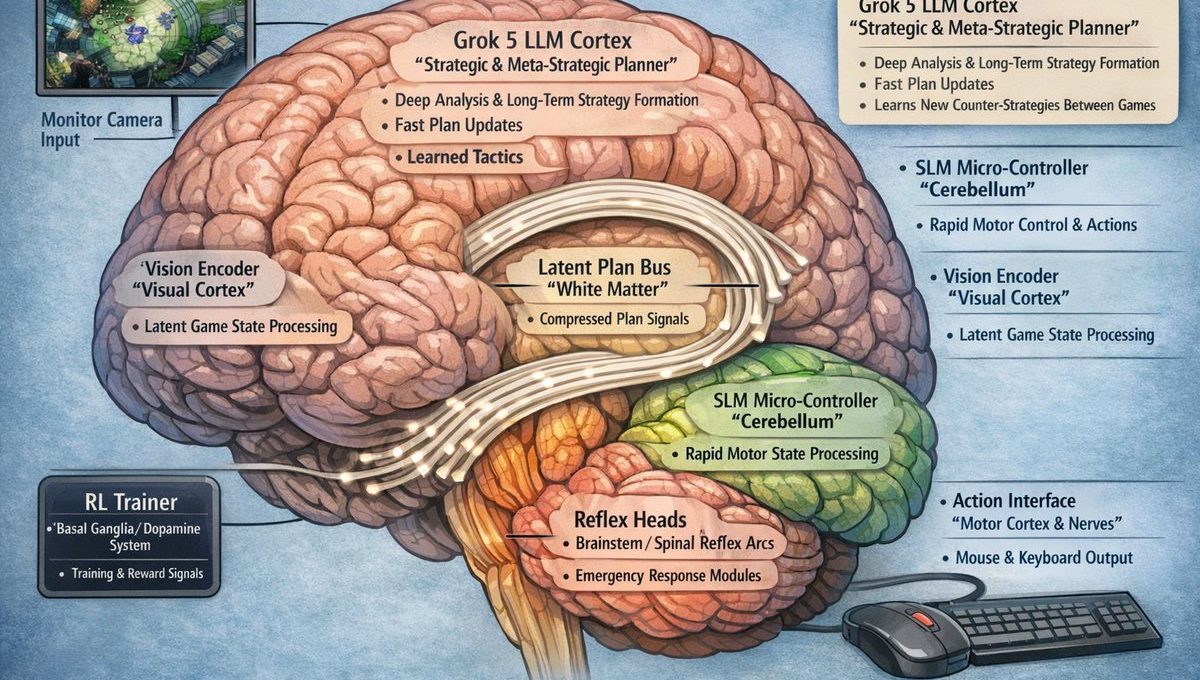
To be good at both real-time decision-making and chain-of-thought reasoning, I believe Grok 5 will require additional architectural components to support rapid action selection.
The Hierarchy
🏗️These components would include mechanisms analogous to spinal reflex arcs and a brainstem, allowing the agent to respond to in-game stimuli within roughly 10–50 ms.
Layer 0: Reflex layer – tens of milliseconds
(Spinal reflex / brainstem)
Ultra-fast pattern triggers: “THIS SKILLSHOT → DODGE NOW”
Tiny nets, basically pre-trained macros.
No “thinking”, just pattern → action.
🏗️The architecture would also benefit from a cerebellum-like module capable of extremely fast, System 1–level decisions (such as motor control, camera movement, and unit spacing or positioning) operating on the order of 30–100 ms. In practice, this cerebellum-like function could plausibly be implemented by a small language model (SLM) or a similarly lightweight neural controller.
Layer 1: Cerebellum layer – 30–100 ms
(System 1 thinking, cerebellum)
Handles: movement, combos, positioning, “feel” for fights.
It’s where skill lives.
Runs every 30–100 ms, stays inside the 150 ms reaction budget.
This layer is what actually plays the game second-by-second and does what humans describe as “I just played on instinct.”
🏗️The LLM is the component of Grok 5 to do System 2-level thinking, which includes System 2A for fast reasoning, and System 2B for slow reasoning. During the gameplay, the component of this LLM is just silently watching and analyzing the info from the input. It only interferes the fast decision process after the strategical decision is made. It might perhaps function like a cerebrum.
Layer 2A: Fast LLM-cortex loop – every few seconds
Not inventing brand-new strategies, but choosing among already-learned plans:
“They’re grouping bot → rotate early to defend.”
“We’re strong top side, call Herald now.”
“Stop contesting 5v5, switch to split push.”
This kind of update doesn’t need minutes of reflection, it’s mostly to pick the right known pattern given the current state.
So we can keep a fast LLM-ish loop that:
i) runs every few seconds or at key events (deaths, objectives, big item spikes),
ii) adjusts a compact plan embedding that conditions the SLM,
iii) but doesn’t interfere with micro control in every tick.
🏗️System 2B thinking is a meta-reasoning process with long chain-of-thought done by the LLM. You can imagine a human player, who initially may have no strategical idea on how to counter the strategy from the opponent. And often, the player will describe that his brain feels like blank and empty. After hopelessly losing several games (many minutes or hours), the human brain finally and suddenly comes up a strategy to effectively counter the strategy from the opponent. So, this type of meta-reasoning requires the LLM to think not just during the gameplay, but also during the after-play or the period between games.
Layer 2B: Slow LLM-cortex meta-loop – minutes to hours
(Between-games deep System 2 / “coach mode”)
Here, the LLM cortex:
i) reviews full game logs and replays,
ii) compares many matches,
iii) reasons in big latent space over drafts, enemy patterns, timing windows, and which macro ideas failed and why.
iv) And then invents or refines new strategic ideas:
“Versus this comp, we must avoid early 5v5 entirely and only fight around 2-item spikes.”
“If they always 4-man dive bot at 6, pre-rotate jungle + mid earlier and trap them.”
This can easily take minutes, and it doesn’t need to run during a single match at all. It updates the agent’s “playbook” between games.
👉(2) General-purpose GUI interaction without APIs:
If, using only a camera (i.e., human-level 20/20 vision), Grok 5 could truly beat human professional players, then—because it is generally intelligent—the same agent could use a mouse and keyboard to operate Windows, edit videos, use 3D modeling software, work with Word and Excel, livestream, trade in financial markets, self-drive, play digital music instruments, and more. No specialized APIs would be required. The agent would visually and directly interact with user interfaces designed for humans. This would be a genuine game changer for AI agentic capability, and these skills could later transfer to ambidextrous physical robots, such as Optimus.
Overall, if Grok 5 can defeat human professional players in real time, it would be an early signal of AGI. It would extend the domains in which large language models already excel into an entirely new and previously inaccessible territory.
Now, the question is: 😰
Is it possible to build such system in 2026 which is not only generally intelligent but also make real-time decisions?
My answer:
We currently have some early signs, such as Genie 3 from Deepmind.
But some people may counter:
“Genie 3 is not a “player” model like a game agent; it’s a world model (a neural environment) that generates the next frame of an interactive world in response to user actions.”
However, some core Genie 3 features weakens the fear that “large neural models can’t run in real time”.
A) Real-time, action-conditioned frame generation (interactive at 24 fps)
Genie 3 can generate a navigable world in real time at 720p and 24 fps. Conceptually, it’s doing a loop like:
(previous frames + your action) → next frame
That’s “real-time neural simulation”: the model is effectively functioning like a neural game engine.
B) Minutes-long-horizon consistency with growing history
Genie 3’s interactivity isn’t just “fast”; it also maintains consistency across time. During auto-regressive frame generation, it has to keep track of an expanding trajectory. If you revisit a location after a while, the model needs to refer back to relevant information from earlier in the session.
This is important because it demonstrates a kind of working memory / state tracking in a generative system, rather than generating each frame independently.
C) Promptable world events (text-based interventions)
Beyond joystick/WASD navigation, Genie 3 allows text prompts to change the world (weather changes, adding objects/characters, triggering events). That matters because it creates a much richer curriculum of “what if” scenarios. This is useful for training robust agents.
Therefore, Genie 3 is telling us that real-time + consistency is possible, it also slightly shifts the bottleneck discussion from “impossible” to “engineering + architecture”. Genie 3 suggests the real question isn’t “can neural models with reasoning run in real time?” but:
i) what architecture makes real-time feasible?
ii) how do you handle growing context efficiently?
iii) what gets cached, summarized, or compressed?
iv) what hardware / compilation / quantization tricks are needed?
In other words, it turns “real-time neural worlds” from a sci‑fi assumption into a concrete systems problem.
Even though Genie 3 is an environment model, it still supports the broader thesis:
Large neural systems can operate in tight loops. Real-time constraints can be met if the design is multi-timescale (fast loop for immediate updates, slower loop for longer reasoning).
That doesn’t automatically solve the LoL agent problem (because a LoL agent must do perception → decision → action, not just world rendering). But it does reduce the knee‑jerk skepticism that “big models are simply too slow.”
So, the later 2026 or 2027 is not an over-ambitious timeline. 🤟
I want to break down how challenging the setup is and how fundamental the breakthrough will be. It requires abilities to:
– recognize a computer interface from a video stream, w/o APIs
– reason with complexity under tight time limits
– execute actions on a computer w/ no need of… https://t.co/eWNcYsi0Jd— Shen Zhuoran (@CMS_Flash) November 26, 2025